SmlOS十一-多任务支持
操作系统是如何实现任务并行的
这里的任务可以理解成进程或者线程操作
不知道有没有同学对此表示过好奇,多个进程如何做到同时运行且不相互影响的。
也许操作系统课上有这样解释过,两个任务线程不停的快速切换,看起来就像是同时运行了一样。
说的没错,不过只有亲自实现一遍,才能对此有深刻的理解。
时间片轮转
先来说下任务切换的原理,其实很简单。
假如我们有只有两个任务A和B,每个任务的时间片是100ms。
刚开始是A在运行,过了100ms,由时钟中断打断了,在中断中,把A所有的寄存器的值保存在一个地方,这个操作我们称之为保存现场。
然后把B任务的所有寄存器从内存恢复到寄存器,这时候就已经完成一次任务切换了。
然后又过了100ms,把B任务保存现场,载入A任务的当时所有寄存器的值,从此循环往复。
简单来说,任务切换就是切换了一堆任务寄存器。
有人可能觉得好奇,这是为什么呢?
这里我们举个例子:
假如A任务的指令序列是:
地址 汇编指令
0x100 mov eax, 1
0x102 add eax, 2
0x104 add eax, 3
eip = 0x100, eax = 0
B任务的指令序列是:
地址 汇编指令
0x200 mov eax, 2
0x202 add eax, 4
0x204 add eax, 8
eip = 0x200, eax = 0
eip = 0x100 代表下一条运行的指令就是0x100地址处的指令
以上面的情景为例,A任务的起始eip是0x100
然后执行了一条指令,这时A现场:
eip = 0x102
eax = 1
我们假如这一条指令执行了100ms,发生了时钟中断,这个时候进行了任务切换,那么会做什么呢?
这个时候先把A现场保存,然后把B任务现场的寄存器,全部恢复,这时cpu寄存器:
eip = 0x200
eax = 0
这时就切换到B的任务中了。
而cpu执行指令只会看eip寄存器指向。
B也执行了一条指令,这时:
eip = 0x202
eax = 2
假如这条指令花费了100ms,又要切换回A任务了,这时候会把刚刚保存的A现场恢复:
eip = 0x102
eax = 1
然后A执行了一条指令,
0x102 add eax, 2
然后eax会变成3,当然: 如果没有任务切换的话,eip执行到这里,eax也是3
你就会惊奇的发现:
我们的任务切换并没有影响到各自任务的执行结果,它和只运行单个任务运行是一样的
当然,我们这里只是拿两个寄存器来说明原理,其他寄存器也是很重要的。
TSS硬件跳转
什么是TSS呢:
TSS (Task State Segment) 任务状态段
暂且把它理解成一个包含了各种寄存器的结构体:
struct TSS32
{
int backlink, esp0, ss0, esp1, ss1, esp2, ss2, cr3;
int eip, eflags, eax, ecx, edx, ebx, esp, ebp, esi, edi;
int es, cs, ss, ds, fs, gs;
int ldtr, iomap;
};
比如说我们要自己实现任务A现场保存,并且切换到B任务。
我们要怎么做呢,我们需要把A任务各种寄存器都手动保存到内存,然后把B任务寄存器都从内存加载到寄存器。
这需要写很多汇编指令。
然后intel提供了一种基址,让你可以“一键跳转”,这就是TSS。
使用TSS跳转是很古老的任务切换机制,比如在linux 0.11内核版本上就是使用TSS,现代操作系统已经不再使用
TSS跳转的细节
在任务切换的过程中,每个处理器寄存器的值保存到由TR任务寄存器指定的TSS。
而任务的跳转则由一条汇编指令jmp far实现
不过在执行farjmp之前需要在GDT里首先注册好TSS的地址。
这样在farjmp之后,CPU会自动保存相应值到TSS里面,然后这个TSS所保存的寄存器的值会被取出还原到各个寄存中去,从而实现了任务现场的恢复,实现了任务的跳转
科普:什么是远跳转
当然程序的跳转分为两种跳转
一种是near模式跳转和far模式跳转。
一般跳转的实现是更改EIP寄存器的值来实现,
在near模式跳转中,只是改写EIP寄存器的值
在far模式中不仅改变EIP,而且还要改变CS寄存器值。
任务优先级设定
那么为什么需要任务优先级呢?
以上面的例子为例,每个任务都是执行100ms然后就开始切换任务。
但是我认为A任务比较重要,需要给200ms的执行时间,给B任务100ms时间,我们要怎么做呢?
在现代的计算机操作系统中,任务的切换动作在0.01-0.03秒左右。
现代的操作系统,对任务的都可以有自定义时间片的分配。
即在执行不同任务的时候,分给任务执行的时间是不同的。
说下我们的实现,介绍下保存单个任务信息的结构体:
struct TASK
{
int sel, flags;
int level;
int priority;
struct TSS32 tss;
struct FIFO32 *fifo;
};
sel 该任务的段选择子(GDT中的选择子)
flag 标识该任务的状态
level 任务运行运行层上(越低层优先运行)
priority: 优先级(时间片长度,这里命名不是很好。。)
tss: TSS数据结构
fifo 该任务缓冲区
切换到指定任务之前,首先设置prioriy指定的超时时间比如设定200ms,那就200ms后才发生切换。
超时功能,之前的章节有讲述。
这样能做到什么效果呢?
我们就实现了两个任务:
A和B:
void task_a()
{
...
int count = 0;
for (;;)
{
count++;
// 显示到窗体
print_count(count);
}
}
void task_b()
{
...
int count = 0;
for (;;)
{
count++;
// 显示到窗体
print_count(count);
}
}
我们设定了这样两个任务,任务操作是一样的:都是执行累加操作。
但是我们任务设置了不同的时间片,A任务运行10ms就切换,而B任务运行20ms才切换。
运行结果:
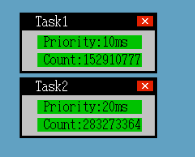
可以看到B任务的累加次数大致是A任务的两倍。
任务分层
当然,仅仅有设置任务的时间片是不够的。
在现实中,往往有更紧急的任务需要去执行。
比如同时有音乐播放任务和网络接收任务。
那么在有网络接收任务的时候,应该优先处理完网络任务,再处理音乐播放任务。
这种优先不是说给网络任务更多的时间片,而是说在有网络任务都会优先区执行网络任务,等执行到没有了网络这种紧急级别的任务,才会考虑执行音乐播放等不重要任务。
因为网络任务是比较重要的,延时接收是可能引发协议超时重传的。
那么这样的需求下,多任务的分层管理结构应用而生。
在这种架构下,即使任务的时间片相同,也会执行层级最高的任务,等高层任务执行完毕,才会执行底层任务。
这里我们引入了层级的概念,比如说网络任务就是高层的任务,音乐播放就是底层任务。
所以这里看下任务管理表的结构体:
struct TASKLEVEL
{
int running;
int now;
struct TASK *tasks[MAX_TASKS_LV];
};
running: 该层中有多少个任务在运行
now: 该层中正在运行的是哪个任务
tasks: TASK的指针数组
struct TASKCTL
{
int now_lv;
char lv_change;
struct TASKLEVEL level[MAX_TASKLEVELS];
struct TASK tasks0[MAX_TASKS];
};
now_lv: 当前任务运行在哪层上(lv==level)
lv_change: 下次任务切换时,是否需要修改level
任务切换核心操作:
//任务切换函数
void task_switch(void)
{
//当前层
struct TASKLEVEL *tl = &taskctl->level[taskctl->now_lv];
struct TASK *new_task, *now_task = tl->tasks[tl->now];
tl->now++;
if (tl->now == tl->running)
{
tl->now = 0;
}
if (taskctl->lv_change != 0)
{
//寻找最上层的level
task_switchsub();
//更新tl让它指向最上层的level
tl = &taskctl->level[taskctl->now_lv];
}
new_task = tl->tasks[tl->now];
timer_settime(task_timer, new_task->priority);
//只有一个任务不跳转
if (new_task != now_task)
{
farjmp(0, new_task->sel);
}
return;
}
任务的休眠
对单个任务的休眠暂停操作就是,从任务表中删除,不参与内核任务切换。
//删除任务
void task_remove(struct TASK *task)
{
int i;
struct TASKLEVEL *tl = &taskctl->level[task->level];
//寻址task所在位置
for (i = 0; i < tl->running; i++)
{
if (tl->tasks[i] == task)
{
break;
}
}
tl->running--;
if (i < tl->now)
{
tl->now--;
}
if (tl->now >= tl->running)
{
tl->now = 0;
}
//休眠中
task->flags = 1;
//整理tasks数组
for (; i < tl->running; i++)
{
tl->tasks[i] = tl->tasks[i + 1];
}
return;
}
内核休眠任务
很多时候计算机是没有任何任务的,但计算机总要有个任务在执行,不能跑飞了。
而且这个任务不能是死循环,太费电。
所以intel出了了 HLT 这个汇编指令。
执行这条指令后,会让cpu进入休眠状态,等到有中断的情况下才会唤醒cpu
而且基于我们的任务分层机制,我们把这个任务放到最底层。
也就是没有其他任务的时候,才会执行这个任务。
在现代操作系统中的,比如windows 中的System Idle Process(系统空闲进程),大致就是这个原理。
还可以基于这个,统计出这个任务的占用时间,从而计算出现在cpu的利用率。
核心代码如下:
_io_hlt: ;void io_hlt(void);
HLT
RET
// 闲置时任务
void syshlt(void)
{
for (;;)
{
io_hlt();
}
}
发表回复
要发表评论,您必须先登录。